



In the past few years, we have witnessed exponential growth in the usage of electronic devices, ranging from desktop computers to mobile phones, to perform various operations. We rely on these machines for simple everyday tasks such as browsing the web, sending and receiving emails, or accessing social networks. Or to perform more specialised work, such as finding the optimal solution to a decision-making problem, simulating complex physical phenomena or determining the prime factors of an integer number.
Even though the electronic devices we use today look very powerful and "smart", it should be noted that they would not be capable of performing any of the above tasks unless instructed explicitly on how to do it. A program is a way to "teach" computers (and similar devices) how a given task should be performed.
In general, a sequence of operations devised to solve a particular problem or to perform a given task is referred to as an algorithm. When an algorithm is translated into a language a computer can understand, it becomes a program. However, this process is more complex than it sounds. We will dive into how programs are encoded and executed in the remainder of this article.
Computer Architecture
Almost all of the computing devices we use today are built according to the system architecture named after the mathematician John Von Neumann, who proposed it, together with others, in 1945. This is shown in the figure below.
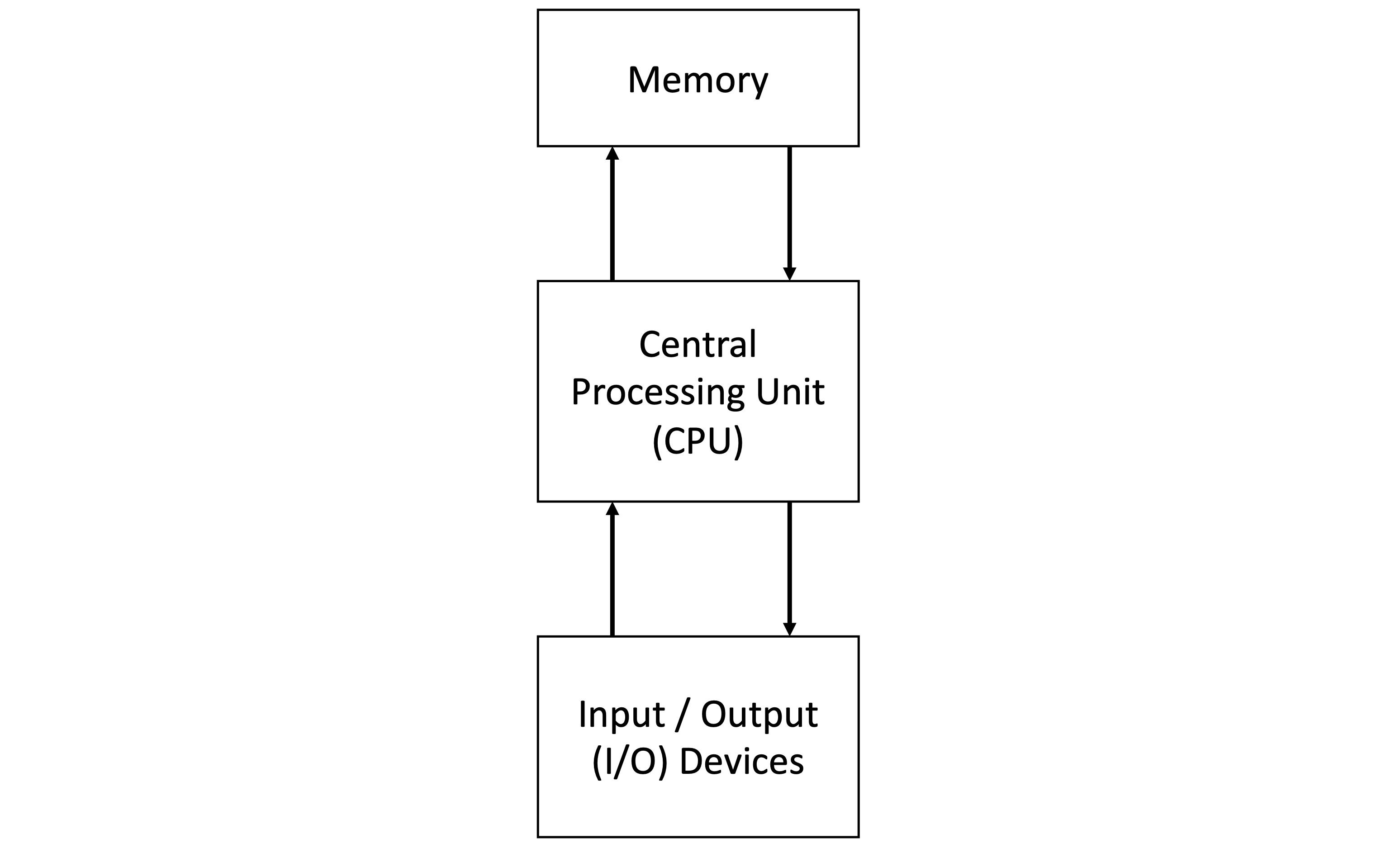
At the core of the Von Neumann architecture are the Processor (CPU – Central Processing Unit) and the Memory (RAM – Random Access Memory). The operations associated with a computer program are called instructions. When a program is executed, its instructions and any data it will process are loaded from the storage device (I/O devices, such as a hard drive or SSD) into the computer’s Memory. The operating system manages this loading process. Once in Memory, the instructions are sequentially fetched by the CPU. This retrieves each instruction from Memory, decodes it to understand the required operation, and then executes it. This cycle of fetching, decoding, and executing instructions continues until the program completes its execution.
In today's computing devices, these hardware components are built as digital circuits, i.e., electric circuits where the signal can be either of the two discrete levels 0 / 5 Volts. These voltage levels represent information by mapping 0V to the bit '0' and 5V to the bit '1'. Finally, these bits, also known as binary digits, are combined into sequences that are utilised to encode both the programs' instructions and the data to be processed.
In the past, computers were different. Ada Lovelace is recognised as the person who wrote the first computer program ever. The computer she used was a mechanical device—Difference Engine—invented by Charles Babbage in the 1820s. How her program was encoded differs from the approach we use today.
These binary instructions are also referred to as machine code (or native code). A sequence of binary digits univocally identifies each instruction. The voltage levels associated with those digits activate specific components of the CPU when a given instruction is loaded. This mechanism allows the CPU to perform arithmetic operations on data, such as addition, subtraction, and multiplication; data can also be loaded, copied and moved from different memory locations. The CPU performs these operations by first loading the data to be processed into its internal storage areas called registries.
For example, the animation in the following figure shows a sequence of CPU instructions that adds the content of memory locations 21 and 22. The CPU first loads data from those memory locations into its internal registries R1 and R2. When the addition is performed, the result is temporarily stored inside the registry R1 and copied to the destination, i.e., the memory location 24.

Now, you may wonder how complex programs to solve the challenging problems mentioned at the beginning could be developed using those elementary instructions. Whilst this would not be impossible, it would still be very complicated and require considerable effort.
First, a programmer would have to be familiar with the instructions set of the CPU on which their program will run. Then, after designing an algorithm for the problem they want to solve, they would have to encode it using such a set of low-level machine code instructions. Finally, they would need to manipulate the data on which those instructions operate by explicitly referring to addresses of the memory and registries of the CPU.
Luckily, today's programming languages provide different abstractions that allow software developers to encode their algorithms using a high-level approach. In this way, the raw manipulation of bits and the direct exposure of the underlying hardware details to the programmer is no longer required.
Programming Languages
Programming languages provide a notation for writing programs in a way that, compared to machine code, is closer to human natural languages. Source code is the term used to indicate a program written in a (high-level) programming language. As the figure below shows, programming languages can support different levels of abstraction according to how close they are to the hardware (at the bottom) or human natural languages (at the top).
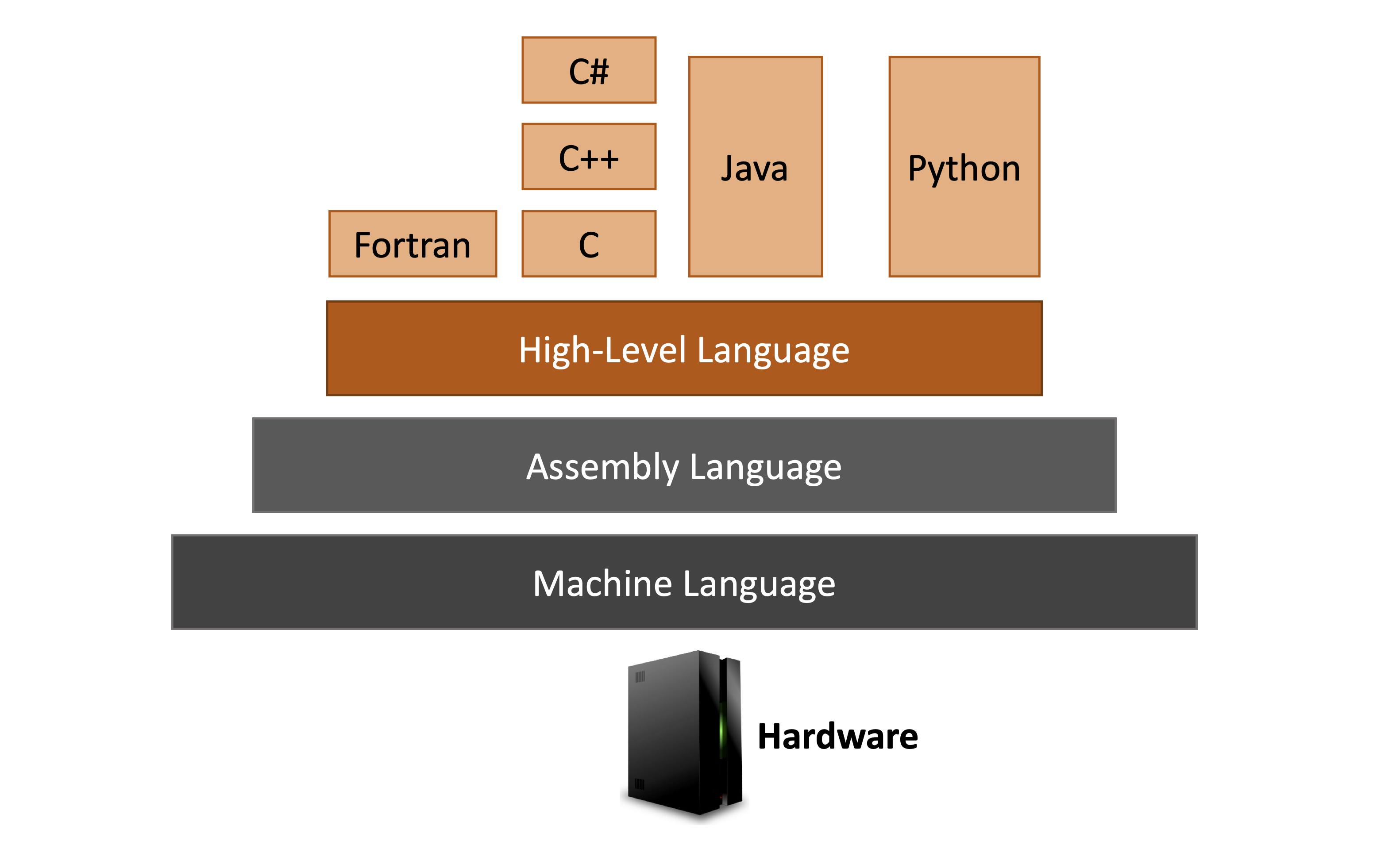
No matter what the provided abstraction is, a computer can only understand and execute the machine code of its CPU; hence, a conversion of a program source code into the corresponding machine code is required before the actual program execution can occur.
Particular pieces of software, known as compilers, deal with the above conversion. In the rest of this article, we will discuss two alternative scenarios. In the first one, starting from the program's source code, a compiler generates machine code that the CPU can execute directly. In the second one, the source code is compiled into an intermediate form called bytecode (or intermediate code in .NET), which is then executed through an application virtual machine.
Compiling Source Code to Machine Code
In this scenario, the source code is given as input to a compiler and translated directly into the machine code of a specific CPU, i.e., usually the one of the system where that compiler is running. The generated machine code will be specific to that hardware and only work on that system. For instance, looking at the figure below, the machine code generated by the light blue compiler will only run on the blue hardware. Similarly, the machine code generated by the light green compiler will only run on the green hardware, even though the same source code is given as input to both compilers.

The green and blue machine codes are not interchangeable: each compiler generates machine code that is customised (and optimised) to run on that particular system. We say that the generated machine code is not portable. This happens when you compile a C or C++ program, for example, and generate an executable file. Machine code does not require further runtime conversions, so its execution is performed directly by loading the code into RAM, and it is usually faster than running the bytecode (or intermediate code) discussed in the next part of the article.
Compiling Source Code to Bytecode
In this scenario, when a program's source code is compiled, it is not translated directly into machine code. Instead, as it typically happens for programs written in high-level languages like Java, C# or Visual Basic, the source code is compiled into an intermediate representation; then, this intermediate code is executed through a runtime environment that provides services like automatic memory management, security, and exception handling, as well as higher portability.
Specifically, this intermediate code is called bytecode according to the terminology adopted by many modern programming languages (including Java and Python). Microsoft .NET-related languages, such as C#, F# or Visual Basic, refer to this type of code as Intermediate Language (IL).
The bytecode (or the IL) is a low-level binary code representation not coupled to specific hardware. It targets an application virtual machine that can execute the bytecode without explicitly producing the associated machine code as output.
What are the advantages of this approach compared to the previous scenario?
The first advantage is the higher level of portability brought about by an application virtual machine. Specifically, once a program is written and compiled, the generated bytecode can be executed seamlessly on any application virtual machine supporting that type of bytecode. For example, different Java Virtual Machine (JVM) implementations exist for various hardware and operating systems. Still, all these JVMs can execute the same bytecode without requiring changes or customisations.
The second advantage is that the program execution is restrained within a self-contained environment (i.e., the application virtual machine) that provides automated memory management, increasing safety and decreasing the likelihood of crashes on the host machine.
The figure below shows two types of systems (blue and green) with their application virtual machines. A compiler first translates the source code into the associated bytecode. Then, at runtime, the bytecode is provided as input to an application virtual machine that executes the program 'line-by-line' and abstracts the underlying hardware and operating system.

In the above model underpinning the execution of bytecode, the application virtual machines is an example of an interpreter. Traditionally, an interpreter is software that takes a high-level program specification as input and executes the instructions sequentially without producing any machine code as output. A classic example of an interpreter is a command line interface implemented via a shell, such as the Bash. The bytecode that application virtual machines execute is a low-level binary format that results from the initial compiling process. This brings significant performance optimisation to the traditional interpreter model.
There was a clear distinction between compilers and interpreters in the past, but the differences have become more blurred recently. As said, application virtual machines interpret the bytecode directly without generating machine code. However, to improve performance, application virtual machines can also use a method called just-in-time (JIT) compilation, where machine code is produced (and stored internally for future use) when a set of bytecode instructions (like a function) is executed for the first time. Moreover, some Java and .NET Software Development Kits (SDKs) offer tools to create precompiled code using ahead-of-time (AoT) compilation to enhance the startup time of applications.
It should be noted that regardless of the approach used to execute the bytecode, the corresponding application virtual machine will always be required for that type of bytecode. This differs from the earlier approach, where a program can execute without additional software after its source code is translated into machine code.
Java Platform
Java is a software stack designed by Oracle that is built on the concepts of intermediate code executed via an application virtual machine. In Java terminology, the source code compiled into intermediate code is called bytecode. The figure below shows that the Java code is compiled to produce a bytecode that can run transparently on any Java Virtual Machine (JVM) version.

The JVM is the application virtual machine that runs the Java bytecode. The other essential components of the Java ecosystem are the compiler that generates that bytecode (e.g., javac in the figure) and a set of ready-to-use library functionalities known as the Java Class Library (JCL). A library can be seen as a pre-compiled piece of bytecode that provides various functionalities programmers can reuse in their code.
The System.out.println() instruction, for example, allows messages to be printed on the console terminal of an operating system. This instruction can be used in a program without requiring the programmer to understand how the operating system manages the console terminal. This is a crucial concept related to libraries. By using the System.out.println() instruction, the programmer does not need to know how messages are encoded and streamed to the terminal. This has already been solved and provided to programmers as part of the Java Class Library. The principles of reusing code and modularity provided by libraries are essential for designing complex software systems that can be easily maintained.
.NET Framework
Like Java, .NET is a software stack (designed by Microsoft) built on the concepts of intermediate code executed via an application virtual machine. In the .NET terminology, the source code compiled into intermediate code is called managed code. The figure below shows that different languages, like C#, F#, or Visual Basic, can be used in .NET to write a program's managed code. This code is then compiled to produce the intermediate code—Common Intermediate Language (CIL)—that can run transparently on any version of the .NET application virtual machine.
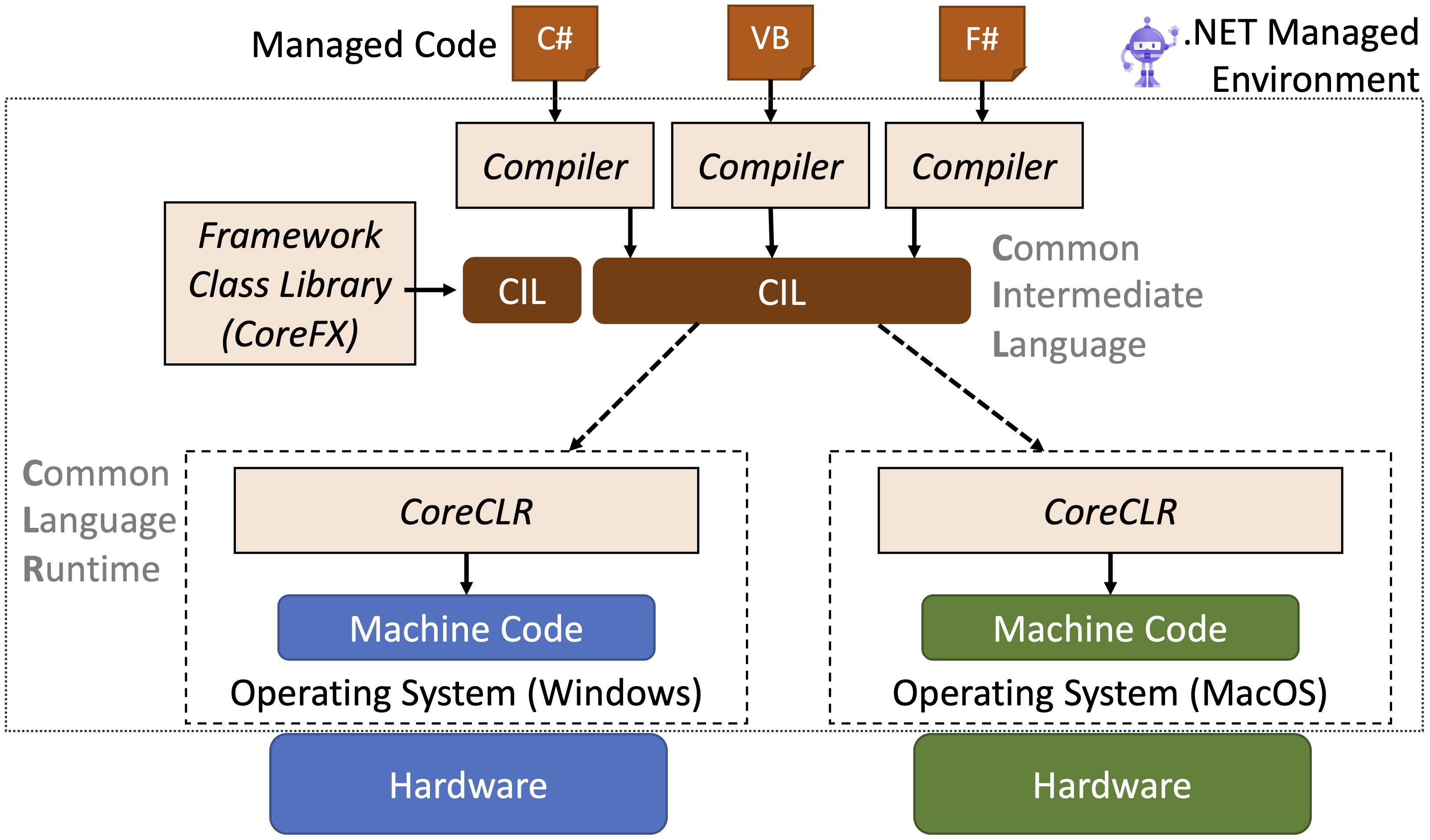
The Common Language Runtime (CoreCLR) is the .NET component (application virtual machine) that runs the CIL code. The other essential components of the .NET framework are the compilers that generate that CIL code and a set of ready-to-use library functionalities known as the Framework Class Library. As seen for the Java scenario, a library is a pre-compiled piece of CIL code that provides a specific functionality.
An example of this in the .NET context is the Console.WriteLine() instruction that, like the System.out.println() seen above, provides an abstract way for a programmer to print messages on the console terminal of an operating system. By using the Console.WriteLine() instruction, the programmer does not need to know how messages are encoded and streamed to the terminal. This has already been solved and provided as one of the Framework Class Library functionalities.
The next article will describe the basic structure of a computer program. It will provide source code examples written in Java and .NET C#.